For the past one week I have been working on part 2 of the series (refer to the overview of the series here - https://healthinterconnect.blogspot.com/2025/04/amazing-power-of-hl7-fhir-supercharged.html ). This time my purpose is to create CRUD page for Encounter resource based on its FHIR resource structure definition. It took longer than I expected, probably took about more than 8 hour.
There are few challenges
1) Even though the FHIRResourceUIDevGuide.md is able to generate the dynamic CRUD page based on Encounter resource structure definition, however these fields do not work properly - CodeableConcept or Coding such as Encounter.class, or fields which refer to other resources eg Encounter.serviceProvider. I think it took me more than 20 iterations so that the dropdown for these fields are showing correctly
2) After these dropdown fields are showing correctly, still spent few iterations to make sure the UI shows the selected field
3) Another issue is that the AI does not work consistently. For example when I asked Copilot to generate PatientCrudPage, some of the previous prompts working in EncounterCrudPage are not rendering the same outcome in PatientCrudPage.
My key takeaway for part 1 is that AI can help me start very fast, however during part 2, the key take away is that it starts to get slower, and I am starting to get prompt fatigue.
Thus for part 2, I will continue to use the EncounterCrudPage created to refine the original prompt instructions in FHIRResourceUIDevGuide.md , hopefully it will be getting smarter and smarter, and reduce the iterations of prompt
However in general, the GenAI is still very impressive, below is few example
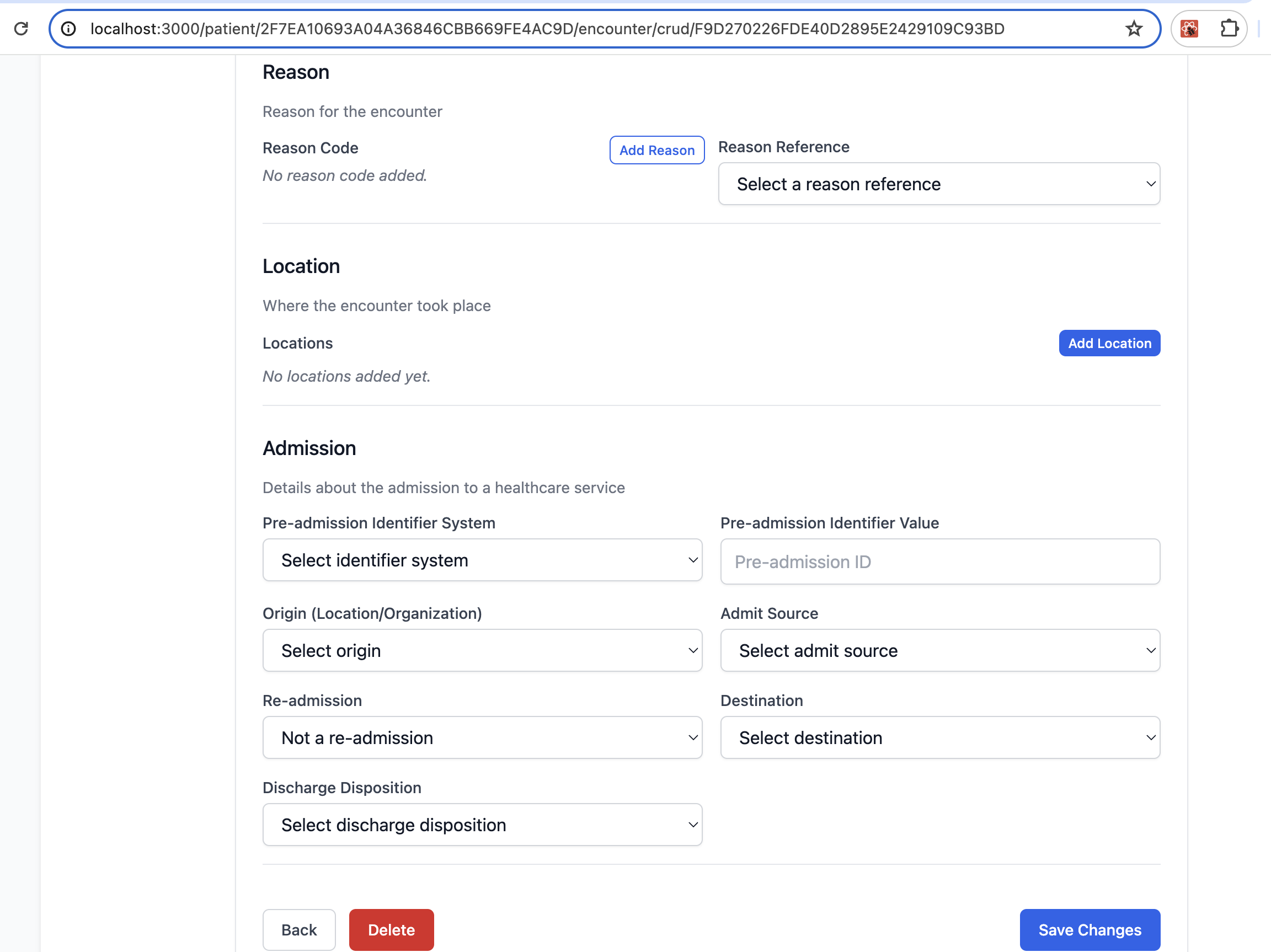
1) I asked Copilot to organize the UI layout of the data elements based on FHIR resource structure. Take the use case of Encounter resource, I asked Copilot to arrange the data elements directly under Encounter resource root level as "Overview" section, and the elements under Encounter backbone level in the respective groups - Diagnosis, Participant, Reason, Location and Admission
2) Initially the dropdown input is not working, it encountered error upon saving, as the field is immutable, it is able to identify the root cause and fixed the issue
GitHub Copilot
I see the issue now. The errors in the console indicate that we're trying to modify objects that are immutable. This typically happens when React's strict mode is enabled or when the state objects are frozen. Let's make deep copies of the objects before modifying them.
Let me fix the error by updating the handleInputChange function to ensure we're creating new objects rather than trying to modify existing ones:
Below is the screnshot of the generated Encounter Crud Page, you can check out the source code at https://github.com/sg-victorchai/gep-poc and run locally.